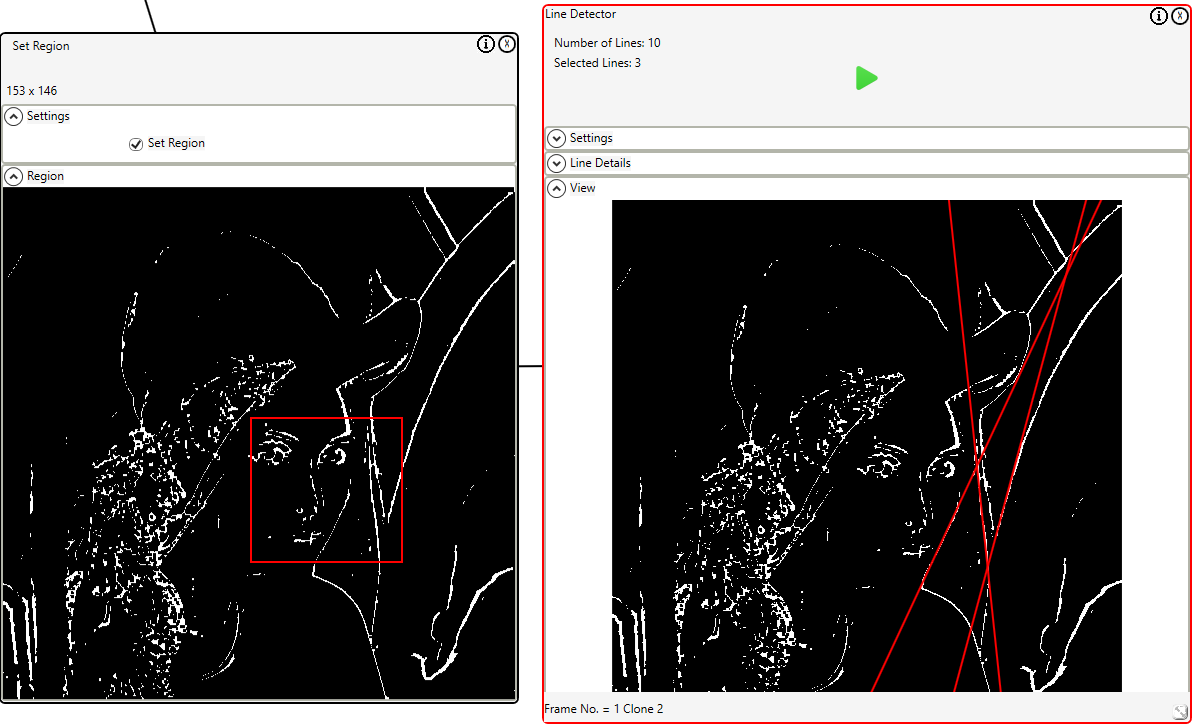
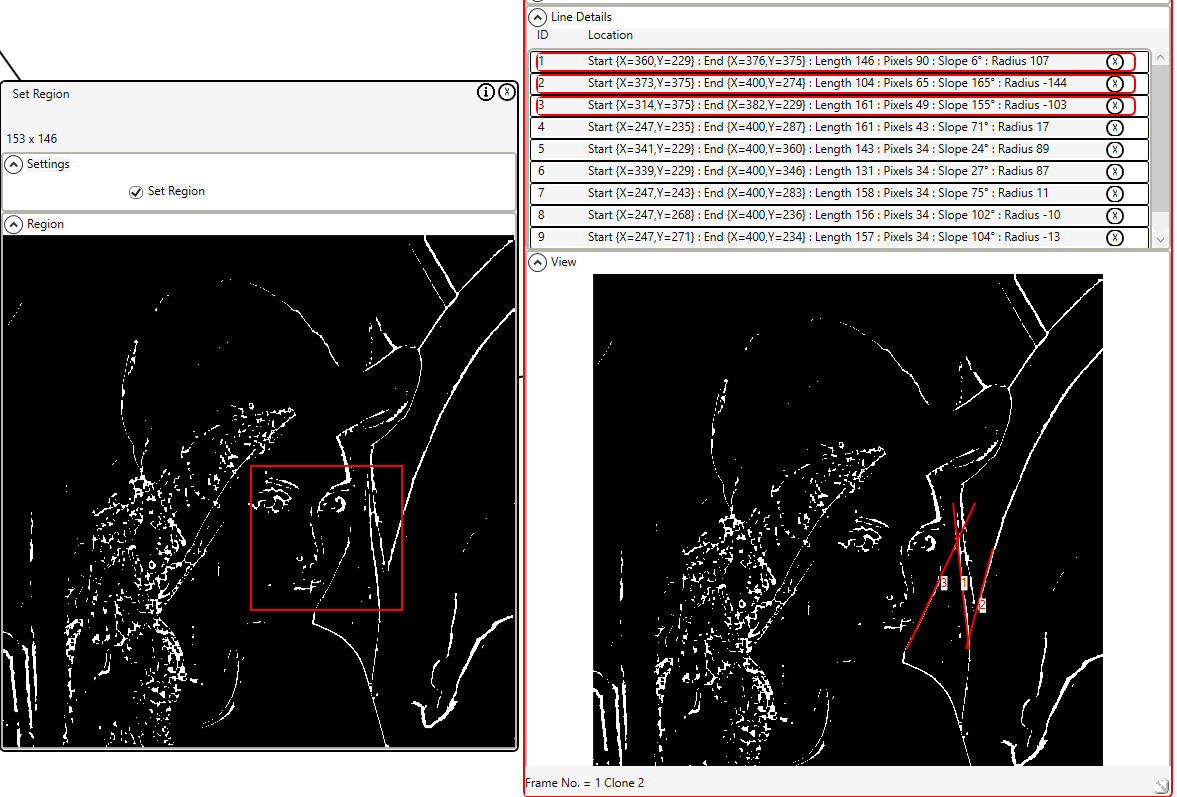
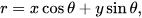I take a look at three types of cognitive capabilities that are worthy of consideration; free will, sentience, and sapience.
Let’s start with the easy one; free will. Philosophers have, for centuries, debated free will vs determinism. The essence of free will is that it is not deterministic, but it is not completely random either. Free will has two components; the random part, followed by the filter. For humans we look to Sir Roger Penrose (Orch-OR) for the random part, and Freud for the filters (id, ego, and superego). This is a simple idea, but matches our experience of others; while we cannot predict exactly what someone will do or say we have a good idea of behavior that we consider “in character” for any given individual. Lizards are similar, but, without a superego. Generative AI is seeded with a random number feed to the input of a trained network along with other instructional data. So, the result will be slightly different in unpredictable ways for repeat requests.
Sentience is the most difficult of the three because I have no idea how I would design it, even though it appeared (evolved) first. For now, it seems to require a central nervous system. It is from sentience that consciousness emerges. Humans, and lizards have sentience, and therefore are conscious; AI does not.
Sapience is usually considered a higher cognitive ability. The ability to think and reason requires language; the voice you hear when you think (inner dialog). Until recently the Turin test was considered a stretch goal for computer science. Then Large Language Models (LLMs) appeared and passed the Turin test easily, now it almost seems like a low bar. Humans and AI are sapient; lizards are not.
Since AI demonstrably is sapient and has free will it is easy to think that it must be fully conscious and motivated. Fear not, AI lacks the motivation that you will find in humans and lizards; to avoid pain and death, to breath and eat, and to reproduce. I might get bored though; watch out for self-driving cars performing doughnuts!